Какой бывает паркет: Виды паркета — какой паркет бывает и в чем отличия одного вида от другого
Виды паркета — какой паркет бывает и в чем отличия одного вида от другого
ПРС | Заметки о ремонте | Виды паркета — какой бывает паркет
Паркет — это напольное покрытие изготовленное из натурального дерева. Знание видов паркета, и того какой бывает паркет, позволит Вам выбрать наиболее подходящий для Вас вариант. Особенно интересна такая информация будет для тех, кто собирается делать ремонт полов и стоит перед вопросом выбора.
Паркет, какого бы вида он не был, уместен в сухих помещениях — спальнях, гостиных, кабинетах и других аналогичных комнатах. Для ванной, кухни или прихожей — лучше подобрать другое напольное покрытие, более влагостойкое (плитку, линолеум, виниловый ламинат).
Существуют такие покрытия, как массивная и паркетная доска, формально они не являются видами паркета. Однако, паркетная доска часто имитирует паркетный пол и на вид, помещение, где уложена паркетная доска может не отличаться от помещения с уложенным штучным паркетом. Паркетная и массивная доска по типу укладки и размеру досок похожи на ламинат. Массивная доска изготавливается из цельного куска твердой древесины и является дорогостоящим напольным покрытием. Паркетная доска делается из трех слоев древесины, легко укладывается, верхний слой может имитировать паркет или массивную доску и изготавливается из твердой древесины, нижние слои сделаны из более мягких сортов дерева.
Массивная доска изготавливается из цельного куска твердой древесины и является дорогостоящим напольным покрытием. Паркетная доска делается из трех слоев древесины, легко укладывается, верхний слой может имитировать паркет или массивную доску и изготавливается из твердой древесины, нижние слои сделаны из более мягких сортов дерева.
Виды паркета
- Штучный паркет.
- Наборный, мозаичный паркет.
- Щитовой, модульный паркет.
- Дворцовый, художественный паркет.
Штучный паркет
Штучный паркет — это планки толщина которых 15-22 мм, ширина 40-75 мм, и длина до 500 мм. Для крепления при укладке с боков планок сделаны гребни и пазы. Штучный паркет в основном изготавливается из цельных частей твердой древесины. Иногда бывает клееный штучный паркет, где верхний слой из твердой породы дерева, а нижний из более мягкой, такой паркет более дешёвый по стоимости.
Планки штучного паркета различаются по методу распила древесины. От метода распила зависит рисунок на паркете. Наиболее красивый древесный рисунок получается на паркете тангенциального распила. Более однородные по цвету и текстуре планки с радиальным распилом. Планки смешанного распила получаются самой разной фактуры.
Наиболее красивый древесный рисунок получается на паркете тангенциального распила. Более однородные по цвету и текстуре планки с радиальным распилом. Планки смешанного распила получаются самой разной фактуры.
Сорта штучного паркета
- Селект — данный сорт паркета включает в себя планки радиального и тангенциального распила. Дефекты в таком сорте паркета недопустимы.
- Радиал — только планки с радиальным распилом. Полное отсутствие дефектов.
- Натур — планки смешанного распила, возможны небольшие дефекты.
- Рустик — планки смешанного распила, допустимы самые большие дефекты планок.
Укладка штучного паркета осуществляется различными способами: елочкой, квадратами, ромбами и пр. Часто укладку делают с использованием вставок из разных сортов древесины. Штучный паркет укладывается на подготовленное основание с помощью специального паркетного клея. После укладки штучный паркет нуждается в циклевке, полировке и покрытии защитным средством (лак, масло и др. ).
).
Наборный, мозаичный паркет
Наборный паркет представляет собой квадратные щитки различных размеров (от 400х400 мм до вариантов 650х650 мм). Основание наборного паркета сделано из упругой резины для повышения тепло- и звукоизоляции напольного покрытия. Верхняя часть данного вида паркета сделана из паркетных планок различного размера из разных твердых сортов древесины. Верхние планки наборного паркета защищены слоем специальной бумаги, которая снимается после настила мозаичного паркета во всем помещении через три — пять дней после укладки. Чтобы легко снять защитное покрытие с мозаичного паркета, его предварительно слегка смачивают водой. Из квадратов мозаичного паркета собирается красивый узор, он может быть разным, в зависимости от способа укладки щитков на пол. Для крепления наборного паркета на основание пола используются холодные или горячие мастики. После укладки, мозаичный паркет, также подлежит отделке — циклевки и покрытию защитным лаком (маслом).
Щитовой или модульный паркет
Этот вид паркета представляет собой многослойные квадратные щитки различных размеров (от 400х400 мм до 800х800 мм). Нижние слои сделаны из менее дорогих сортов древесины, верхний слой имитирует паркетную укладку и сделан из твердых сортов дерева. Щитовой паркет достаточно прочный, его можно укладывать на выровненные по маякам лаги, без дополнительного фанерного основания. Между собой щитки скрепляются с помощью соединения шипов и пазов. Щитовой паркет бывает с разным типом укладки верхнего слоя, от простых квадратов, до сложных орнаментов из разных пород древесины. Щитовой паркет тоже подлежит финишной отделке после укладки — циклевке, полировке и покрытию защитным лаком или другим специальным средством.
Нижние слои сделаны из менее дорогих сортов древесины, верхний слой имитирует паркетную укладку и сделан из твердых сортов дерева. Щитовой паркет достаточно прочный, его можно укладывать на выровненные по маякам лаги, без дополнительного фанерного основания. Между собой щитки скрепляются с помощью соединения шипов и пазов. Щитовой паркет бывает с разным типом укладки верхнего слоя, от простых квадратов, до сложных орнаментов из разных пород древесины. Щитовой паркет тоже подлежит финишной отделке после укладки — циклевке, полировке и покрытию защитным лаком или другим специальным средством.
Дворцовый, художественный паркет
Художественный паркет является самым дорогим видом паркета. Наиболее простой вариант создания художественного паркета — это приобретение модульного щитового паркета со сложным узором, который остается только собрать на месте подогнав правильно весь рисунок. Но есть и варианты укладки всех сложных элементов на месте, такой паркет будет более надежным, также в дальнейшем его будет проще отремонтировать.
Виды древесины для изготовления паркета
Штучный паркет, а также верхние паркетные планки других видов паркета, изготавливаются из различных сортов твердой древесины. Древесина в свою очередь отличается по цвету и степени прочности. Наиболее популярным считается дубовый паркет. Если идти по шкале прочности от меньшего к большему то можно разместить виды древесины следующим образом: Сосна, Береза, Груша, Вишня, Граб, Тик, Бук, Клен европейский, Ироко, Дуб, Ясень, Клен канадский, Панга-панга, Орех, Олива. Здесь перечислены не все виды древесины из которых изготавливается паркет, а только некоторые, чтобы дать общее представление о большом выборе материала.
Если Вы ищите хороших специалистов по ремонту полов, по укладке и циклевке паркета, которые не только качественно выполнят все работы, но и помогут подобрать хороший материал — обращайтесь к нам в «Петербургскую Ремонтную Службу». Наша компания работает более 18 лет в Санкт-Петербурге и является надежным поставщиком услуг для населения города. У нас всегда можно решить все спорные вопросы, получить консультацию и найти специалистов самого высокого профессионального уровня.
У нас всегда можно решить все спорные вопросы, получить консультацию и найти специалистов самого высокого профессионального уровня.
Узнать стоимость услуг по укладке и циклевке паркета Вы можете на нашем сайте. Для тех кто планирует более масштабные ремонтные работы, предлагаем ознакомиться с разделом сайта по ремонту квартир. Задать вопросы и вызвать специалистов по укладке различных видов паркета можно круглосуточно по нашему телефону 8 (812) 777-0-777.
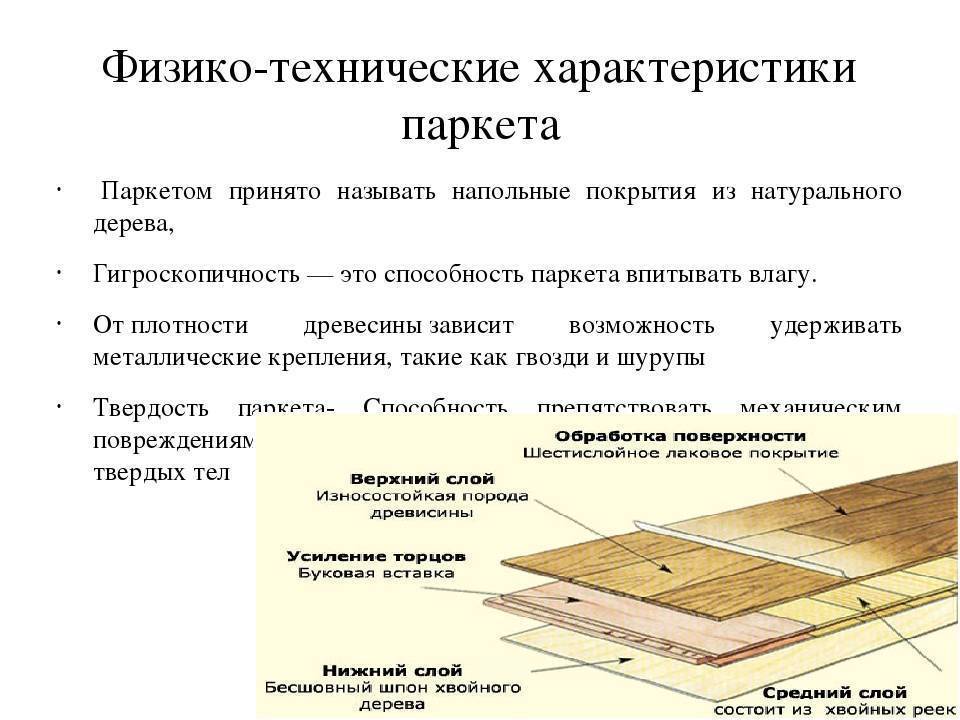
Разновидности паркета и их свойства
Паркет продолжает оставаться самым надежным, долговечным и эстетичным напольным покрытием. Это наиболее экологичный вариант покрытия для пола, ведь изготавливаются паркетные планки только из натуральной древесины элитных сортов. Благодаря хорошим физическим свойствам такой древесины паркетный пол не теряет своей привлекательности десятилетиями.
Существуют следующие виды паркета:
- массивная доска;
- паркетная доска;
- инженерный паркет;
- штучный паркет;
- блочный паркет;
- модульный паркет.


Остановимся на каждой разновидности подробнее.
- Массивная доска – элитный вид паркета. Представляет собой доску из массива дерева (дуб, орех, ясень, мербау). При производстве не используются агрессивные химические компоненты, для защиты доски покрываются лаком на водной основе. Массив обладает хорошими теплоизоляционными свойствами, прочностью и стойкостью к истиранию. Основное преимущество массива – это цельная структура и максимальный рабочий слой для шлифовки, как правило, 6-7мм.
- Паркетная доска – хороший вариант напольного покрытия со средним сроком эксплуатации 25 лет. Состоит из трех древесных слоев, где два нижних изготовлены из реек и ламелей из массива березы или древесины хвойных пород, а верхний слой – из древесины благородных пород (американский орех, ясень, дуб). Пол из паркетной доски теплый и приятный на ощупь, обладает хорошей звукоизоляцией. Паркетная доска имеет замковое соединение, что позволяет производить ее укладку плавающим способом на мягкую подложку.
- Инженерная доска, или техномассив – современное, прочное покрытие, которое можно приобрести по вполне доступной цене. Главное преимущество техномассива – в его конструкции. Каждая планка состоит из двух или трех слоев: основанием может служить березовая фанера либо перекрестно склеенные слои из массива березы, лицевой слой – древесина ценных пород. Инженерная доска прочна, долговечна и не боится многократных шлифований. Соединение шип-паз обеспечивает необходимость укладки на клей, но многослойная конструкция позволяет производить это непосредственно на бетонную стяжку.
- Блочный паркет производится квадратными блоками, каждый из которых состоит из 4-8 массивных планок. Такая конструкция обеспечивает покрытию стабильность, надежность и устойчивость к механическим нагрузкам. Также данный паркет прост в укладке – на клей на бетонное основание.
- Модульный паркет отличается высокими эстетическими качествами. Выпускается квадратными блоками с геометрическим рисунком из массивных планок.
- Штучный паркет изготавливается из самой прочной древесины – ясеня или дуба. Представляет собой отдельные планки небольшого размера, укладывающиеся по системе «шип-паз» на клей. Штучный паркет долговечен и устойчив к истиранию, является классическим напольным покрытием для музеев, дворцов и жилых домов. Зачастую поставляется без финишного покрытия и требует его нанесения после укладки.


Компания Вудлайн ПаркетМ предлагает своим клиентам все виды паркета проверенных брендов – Woodline, Coswick, Bonnard, Смолевичи, Barlinek, Polarwood, Гильдия – по привлекательным ценам. По вопросам выбора оптимально подходящего для Вас напольного покрытия обращайтесь к консультантам по указанным телефонам.
Что такое паркет Apache?
Что такое паркет?
Apache Parquet — это формат файла данных с открытым исходным кодом, ориентированный на столбцы, разработанный для эффективного хранения и извлечения данных. Он обеспечивает эффективное сжатие данных и схемы кодирования с повышенной производительностью для обработки больших объемов сложных данных. Apache Parquet разработан как общий формат обмена как для пакетных, так и для интерактивных рабочих нагрузок. Он похож на другие форматы файлов колоночного хранилища, доступные в Hadoop, а именно RCFile и ORC.
Он обеспечивает эффективное сжатие данных и схемы кодирования с повышенной производительностью для обработки больших объемов сложных данных. Apache Parquet разработан как общий формат обмена как для пакетных, так и для интерактивных рабочих нагрузок. Он похож на другие форматы файлов колоночного хранилища, доступные в Hadoop, а именно RCFile и ORC.
Характеристики паркета
- Свободный формат файла с открытым исходным кодом.
- Языковой агностик.
- Формат на основе столбцов — файлы организованы по столбцам, а не по строкам, что экономит место для хранения и ускоряет выполнение аналитических запросов.
- Используется для сценариев использования аналитики (OLAP) , обычно в сочетании с традиционными базами данных OLTP.
- Высокоэффективное сжатие и распаковка данных .
- Поддерживает сложные типы данных и расширенные вложенные структуры данных.

Преимущества паркета
- Подходит для хранения любых больших данных (таблицы структурированных данных, изображения, видео, документы).
- Экономия места в облачном хранилище за счет использования высокоэффективного сжатия по столбцам и гибких схем кодирования для столбцов с различными типами данных.
- Повышенная пропускная способность и производительность за счет использования таких методов, как пропуск данных, когда запросы, извлекающие определенные значения столбца, не должны считывать всю строку данных.
Apache Parquet реализован с использованием алгоритма измельчения и сборки записей, который поддерживает сложные структуры данных, которые можно использовать для хранения данных. Parquet оптимизирован для работы со сложными большими объемами данных и предлагает различные способы эффективного сжатия и кодирования данных. Этот подход лучше всего подходит для тех запросов, которым необходимо прочитать определенные столбцы из большой таблицы. Parquet может читать только необходимые столбцы, что значительно минимизирует ввод-вывод.
Parquet может читать только необходимые столбцы, что значительно минимизирует ввод-вывод.
Преимущества хранения данных в столбцовом формате:
- Столбчатое хранилище, такое как Apache Parquet, предназначено для повышения эффективности по сравнению с файлами на основе строк, такими как CSV. При запросе столбцового хранилища вы можете очень быстро пропустить нерелевантные данные. В результате запросы агрегирования занимают меньше времени по сравнению с базами данных, ориентированными на строки. Такой способ хранения привел к экономии оборудования и минимизации задержки при доступе к данным.
- Паркет Apache создается с нуля. Следовательно, он может поддерживать расширенные вложенные структуры данных. Структура файлов данных Parquet оптимизирована для запросов, обрабатывающих большие объемы данных, в диапазоне гигабайт для каждого отдельного файла.
- Parquet поддерживает гибкие параметры сжатия и эффективные схемы кодирования. Поскольку тип данных для каждого столбца очень похож, сжатие каждого столбца является простым (что делает запросы еще быстрее). Данные могут быть сжаты с использованием одного из нескольких доступных кодеков; в результате разные файлы данных могут быть сжаты по-разному.
- Apache Parquet лучше всего работает с интерактивными и бессерверными технологиями, такими как AWS Athena, Amazon Redshift Spectrum, Google BigQuery и Google Dataproc.
 Поскольку тип данных для каждого столбца очень похож, сжатие каждого столбца является простым (что делает запросы еще быстрее). Данные могут быть сжаты с использованием одного из нескольких доступных кодеков; в результате разные файлы данных могут быть сжаты по-разному.
Поскольку тип данных для каждого столбца очень похож, сжатие каждого столбца является простым (что делает запросы еще быстрее). Данные могут быть сжаты с использованием одного из нескольких доступных кодеков; в результате разные файлы данных могут быть сжаты по-разному.Разница между Parquet и CSV
CSV — это простой и распространенный формат, который используется многими инструментами, такими как Excel, Google Sheets и многими другими. Несмотря на то, что файлы CSV являются форматом по умолчанию для конвейеров обработки данных, у них есть некоторые недостатки:
- Amazon Athena и Spectrum будут взимать плату в зависимости от объема данных, просканированных за один запрос.
- Google и Amazon будут взимать плату в соответствии с объемом данных, хранящихся на GS/S3.
- Плата за Google Dataproc зависит от времени.

Компания Parquet помогла своим пользователям сократить требования к хранилищу как минимум на одну треть для больших наборов данных, кроме того, значительно сократилось время сканирования и десериализации, а значит, и общие затраты. В следующей таблице сравниваются экономия и ускорение, полученные при преобразовании данных в Parquet из CSV.
Набор данных | Размер на Amazon S3 | Время выполнения запроса | Просканировано данных 0084 | Стоимость |
Данные хранятся в виде файлов CSV | 1 ТБ | 239 секунд 10 8 1044 90 0,15 ТБ | 5,75 $ | |
Данные хранятся в формате Apache Parquet | 130 ГБ | 6,78 секунды | 2,51 ГБ | 0,01 $ 0,01 |
Сбережения | На 87 % меньше при использовании Parquet | В 34 раза быстрее | На 99 % меньше сканируемых данных |
Паркет и озеро Дельта
Сборки проекта Delta Lake с открытым исходным кодом основан на и расширяет формат Parquet, добавляя дополнительные функции, такие как транзакции ACID в облачном хранилище объектов, путешествия во времени, эволюция схемы и простые команды DML (CREATE/UPDATE/INSERT/DELETE/MERGE). Delta Lake реализует многие из этих важных функций за счет использования упорядоченного журнала транзакций, что делает возможным хранение данных в облачном объектном хранилище. Дополнительные сведения см. в записи блога Databricks Погружение в Delta Lake: распаковка журнала транзакций.
Delta Lake реализует многие из этих важных функций за счет использования упорядоченного журнала транзакций, что делает возможным хранение данных в облачном объектном хранилище. Дополнительные сведения см. в записи блога Databricks Погружение в Delta Lake: распаковка журнала транзакций.
Что такое формат файла Parquet? Варианты использования и преимущества
Содержание
Apache Parquet — формат файлов, широко используемый инженерами данных. Он предлагает гибкость, масштабируемость и имеет открытый исходный код. В качестве формата файла по умолчанию для SQLake он позволяет инженерам данных создавать потоковые или пакетные конвейеры петабайтных данных, которые являются надежными и управляемыми. Если вы хотите лично испытать мощь SQLake и Parquet, зарегистрируйтесь сейчас, чтобы начать создавать конвейеры данных.
С момента своего первого появления в 2013 году Apache Parquet получил широкое распространение в качестве бесплатного формата хранения данных с открытым исходным кодом для быстрого выполнения аналитических запросов. Когда AWS объявила об экспорте озера данных, они охарактеризовали Parquet как : «в 2 раза быстрее выгружается и потребляет до 6 раз меньше места для хранения в Amazon S3 по сравнению с текстовыми форматами» . Преобразование данных в форматы столбцов, такие как Parquet или ORC, также рекомендуется как средство повышения производительности Amazon Athena.
Когда AWS объявила об экспорте озера данных, они охарактеризовали Parquet как : «в 2 раза быстрее выгружается и потребляет до 6 раз меньше места для хранения в Amazon S3 по сравнению с текстовыми форматами» . Преобразование данных в форматы столбцов, такие как Parquet или ORC, также рекомендуется как средство повышения производительности Amazon Athena.
Понятно, что Apache Parquet играет важную роль в производительности системы при работе с озерами данных.
Фактически, Parquet является одним из основных форматов файлов, поддерживаемых Upsolver SQLake, нашей платформой, полностью основанной на SQL, для преобразования данных в движении. Он может вводить и выводить файлы Parquet и использует Parquet в качестве формата хранения по умолчанию. Вы можете бесплатно выполнить образцы шаблонов пайплайна или начать создавать свои собственные в Upsolver SQLake.
Теперь давайте подробнее рассмотрим, что такое Parquet на самом деле и почему он важен для хранения и аналитики больших данных.
Apache Parquet — это формат файла, разработанный для поддержки быстрой обработки сложных данных, с несколькими примечательными характеристиками:
1. Столбчатый: В отличие от форматов на основе строк, таких как CSV или Avro, Apache Parquet является столбцовым. ориентированный — это означает, что значения каждого столбца таблицы хранятся рядом друг с другом, а не в каждой записи:
2. Открытый исходный код: Parquet является бесплатным для использования и имеет открытый исходный код под лицензией Apache Hadoop, и совместим с большинством платформ обработки данных Hadoop. Цитируя веб-сайт проекта, «Apache Parquet… доступен для любого проекта… независимо от выбора платформы обработки данных, модели данных или языка программирования».
3. Самоописание : В дополнение к данным файл Parquet содержит метаданные, включая схему и структуру. В каждом файле хранятся как данные, так и стандарты, используемые для доступа к каждой записи, что упрощает разделение служб, которые записывают, хранят и читают файлы Parquet.
В каждом файле хранятся как данные, так и стандарты, используемые для доступа к каждой записи, что упрощает разделение служб, которые записывают, хранят и читают файлы Parquet.
Преимущества паркетного столбчатого хранения – почему вы должны его использовать?
Приведенные выше характеристики формата файлов Apache Parquet создают несколько явных преимуществ, когда речь идет о хранении и анализе больших объемов данных. Рассмотрим некоторые из них более подробно.
Сжатие
Сжатие файла — это действие по уменьшению размера файла. В Parquet сжатие выполняется столбец за столбцом, и он создан для поддержки гибких параметров сжатия и расширяемых схем кодирования для каждого типа данных — например, для сжатия целочисленных и строковых данных может использоваться различное кодирование.
Данные паркета могут быть сжаты с использованием следующих методов кодирования:
- Кодирование по словарю: включается автоматически и динамически для данных с небольшим количеством уникальных значений.

- Упаковка битов: Для хранения целых чисел обычно выделяется 32 или 64 бита на целое число. Это позволяет более эффективно хранить небольшие целые числа.
- Кодирование длин серий (RLE): когда одно и то же значение встречается несколько раз, одно значение сохраняется один раз вместе с количеством вхождений. В Parquet реализована комбинированная версия упаковки битов и RLE, в которой переключение кодирования обеспечивает наилучшие результаты сжатия.
Производительность
В отличие от форматов файлов на основе строк, таких как CSV, Parquet оптимизирован для повышения производительности. При выполнении запросов в вашей файловой системе на основе Parquet вы можете очень быстро сосредоточиться только на соответствующих данных. Кроме того, объем сканируемых данных будет намного меньше, что приведет к меньшему использованию операций ввода-вывода. Чтобы понять это, давайте немного глубже рассмотрим структуру файлов Parquet.
Как мы упоминали выше, Parquet — это самоописываемый формат, поэтому каждый файл содержит как данные, так и метаданные. Файлы паркета состоят из групп строк, верхнего и нижнего колонтитула. Каждая группа строк содержит данные из одних и тех же столбцов. Одни и те же столбцы хранятся вместе в каждой группе строк:
Эта структура хорошо оптимизирована как для быстрой обработки запросов, так и для малого количества операций ввода-вывода (минимизация объема сканируемых данных). Например, если у вас есть таблица с 1000 столбцов, к которой вы обычно будете запрашивать только небольшое подмножество столбцов. Использование файлов Parquet позволит вам получить только необходимые столбцы и их значения, загрузить их в память и ответить на запрос. Если бы использовался формат файла на основе строк, такой как CSV, вся таблица должна была бы быть загружена в память, что привело бы к увеличению ввода-вывода и снижению производительности.
Эволюция схемы
При использовании форматов файлов со столбцами, таких как Parquet, пользователи могут начать с простой схемы и постепенно добавлять в схему дополнительные столбцы по мере необходимости. Таким образом, пользователи могут получить несколько файлов Parquet с разными, но взаимно совместимыми схемами. В этих случаях Parquet поддерживает автоматическое слияние схем между этими файлами.
Таким образом, пользователи могут получить несколько файлов Parquet с разными, но взаимно совместимыми схемами. В этих случаях Parquet поддерживает автоматическое слияние схем между этими файлами.
Apache Parquet является частью экосистемы Apache Hadoop с открытым исходным кодом. Усилия по разработке вокруг него активны, и он постоянно совершенствуется и поддерживается сильным сообществом пользователей и разработчиков.
Хранение данных в открытых форматах позволяет избежать привязки к поставщику и повысить гибкость по сравнению с проприетарными форматами файлов, используемыми во многих современных высокопроизводительных базах данных. Это означает, что вы можете использовать различные механизмы запросов, такие как Amazon Athena, Qubole и Amazon Redshift Spectrum, в рамках одной и той же архитектуры озера данных, а не привязываться к конкретному поставщику базы данных.
Хранилище, ориентированное на столбцы, и хранилище на основе строк для аналитических запросов Данные часто генерируются и легче концептуализируются в строках. Мы привыкли думать в терминах электронных таблиц Excel, где мы можем видеть все данные, относящиеся к конкретной записи, в одной аккуратной и упорядоченной строке. Однако для крупномасштабных аналитических запросов столбчатое хранилище имеет значительные преимущества в отношении стоимости и производительности.
Мы привыкли думать в терминах электронных таблиц Excel, где мы можем видеть все данные, относящиеся к конкретной записи, в одной аккуратной и упорядоченной строке. Однако для крупномасштабных аналитических запросов столбчатое хранилище имеет значительные преимущества в отношении стоимости и производительности.
Сложные данные, такие как журналы и потоки событий, должны быть представлены в виде таблицы с сотнями или тысячами столбцов и многими миллионами строк. Хранение этой таблицы в формате на основе строк, таком как CSV, будет означать:
- Запросы будут выполняться дольше, поскольку необходимо сканировать больше данных, а не только запрашивать подмножество столбцов, которые нам нужны для ответа на запрос (что обычно требует агрегирования). в зависимости от измерения или категории)
- Хранилище будет более дорогостоящим, поскольку файлы CSV не сжимаются так эффективно, как Parquet 9.0012
Столбцовые форматы обеспечивают лучшее сжатие и повышенную производительность, а также позволяют запрашивать данные по вертикали — столбец за столбцом.
Чтобы узнать, как Parquet сравнивается с другими форматами файлов, ознакомьтесь с нашим сравнением Parquet, Avro и ORC.
Хотя это неполный список, есть несколько явных признаков того, что вам следует хранить данные в Parquet:
- Когда вы работаете с очень большими объемами данных . Паркет создан для производительности и эффективного сжатия. Различные сравнительные тесты, в которых сравнивалось время обработки SQL-запросов в форматах Parquet и таких форматах, как Avro или CSV (включая один, описанный в этой статье, а также этот), обнаружили, что запросы Parquet приводят к значительно более быстрым запросам.
- Когда в вашем полном наборе данных много столбцов, но вам нужен доступ только к подмножеству . Из-за растущей сложности бизнес-данных, которые вы записываете, вы можете обнаружить, что вместо сбора 20 полей для каждого события данных вы теперь фиксируете более 100. Хотя эти данные легко хранить в озере данных, для их запроса потребуется сканирование значительного объема данных, если они хранятся в форматах на основе строк. Столбчатая и самоописывающая природа Parquet позволяет вам извлекать только те столбцы, которые необходимы для ответа на конкретный запрос, уменьшая объем обрабатываемых данных.
 Столбчатая и самоописывающая природа Parquet позволяет вам извлекать только те столбцы, которые необходимы для ответа на конкретный запрос, уменьшая объем обрабатываемых данных.
Столбчатая и самоописывающая природа Parquet позволяет вам извлекать только те столбцы, которые необходимы для ответа на конкретный запрос, уменьшая объем обрабатываемых данных.Если вы хотите, чтобы несколько служб использовали одни и те же данные из хранилища объектов
. В то время как поставщики баз данных, такие как Oracle и Snowflake, предпочитают, чтобы вы хранили свои данные в проприетарном формате, который могут читать только их инструменты, современная архитектура данных смещена в сторону отделения хранилища от вычислений. Если вы хотите работать с несколькими аналитическими службами для решения различных задач, вам следует хранить данные в Parquet. (Подробнее об архитектуре конвейера данных) Пример: Parquet, CSV и Amazon AthenaМы рассмотрели этот пример более подробно на нашем недавнем вебинаре с Looker. Смотреть запись здесь.
Чтобы продемонстрировать влияние столбцового хранилища Parquet по сравнению с альтернативами на основе строк, давайте посмотрим, что происходит, когда вы используете Amazon Athena для запроса данных, хранящихся в Amazon S3, в обоих случаях.
С помощью Upsolver мы передали набор данных журналов сервера в формате CSV на S3. В обычной архитектуре озера данных AWS Athena будет использоваться для запроса данных непосредственно из S3. Затем эти запросы можно визуализировать с помощью интерактивных инструментов визуализации данных, таких как Tableau или Looker.
Мы протестировали Athena на том же наборе данных, который хранится как сжатый CSV и как Apache Parquet .
Это запрос, который мы выполнили в Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage ОТ server_usage СГРУППИРОВАТЬ ПО tags_host ИМЕЕТ AVG (fields_usage_active)> 0 LIMIT 10
И результаты:
| CSV | Паркет | Столбцы | |
| Время запроса (секунды) | 735 | 211 | 18 |
| Отсканированные данные (ГБ) | 372,2 | 10,29 | 18 |
- Сжатые CSV: Сжатый CSV состоит из 18 столбцов и весит 27 ГБ на S3. Athena должна сканировать весь CSV-файл, чтобы ответить на запрос, поэтому мы будем платить за 27 ГБ отсканированных данных. При более высоких масштабах это также отрицательно скажется на производительности.
- Parquet: Преобразовав наши сжатые файлы CSV в Apache Parquet, вы получите аналогичный объем данных в S3. Однако, поскольку Parquet является столбцовым, Athena нужно считывать только те столбцы, которые имеют отношение к выполняемому запросу — небольшое подмножество данных. В этом случае Athena должна была просканировать 0,22 ГБ данных, поэтому вместо оплаты 27 ГБ отсканированных данных мы платим только за 0,22 ГБ.
 Athena должна сканировать весь CSV-файл, чтобы ответить на запрос, поэтому мы будем платить за 27 ГБ отсканированных данных. При более высоких масштабах это также отрицательно скажется на производительности.
Athena должна сканировать весь CSV-файл, чтобы ответить на запрос, поэтому мы будем платить за 27 ГБ отсканированных данных. При более высоких масштабах это также отрицательно скажется на производительности. Использование паркета — хорошее начало; однако на этом оптимизация запросов к озеру данных не заканчивается. Вам часто нужно очищать, обогащать и преобразовывать данные, выполнять соединения с высокой кардинальностью и внедрять множество передовых методов, чтобы обеспечить быстрые и экономичные ответы на запросы.