Паркет как выбрать: Как выбрать паркет для дома: пошаговая инструкция — INMYROOM
Как выбрать паркет для дома: пошаговая инструкция — INMYROOM
Ремонт на практике
У прочного и натурального паркета нет конкурентов среди отделочных материалов. Разобраться в том, какой паркет подойдет именно вам, не так уж сложно: для этого мы составили простой гид
У прочного и натурального паркета нет конкурентов на рынке отделочных материалов, но разнообразие видов превращает выбор в непростую задачу. На самом деле разобраться в том, какой паркет подойдет именно вам, не так уж сложно: для этого мы составили простой гид из 5 шагов.
1. Выберите материал
В основном паркет делают из твердой и надежной древесины лиственных пород. Дубовый паркет имеет хорошо выраженную текстуру, а его оттенки варьируются от коричнево-зеленого до черного. Более бюджетный вариант — паркет из бука желто-рыжего цвета с темными прожилками и бело-медовый клен.
В последние годы на рынке появился паркет из экзотических пород дерева — бамбука, махагона и тика. Они лучше переносят воздействие влаги и перепады температур. Кроме того, бамбуковый паркет считается самым экологичным отделочным материалом: стебли бамбука растут слишком быстро, чтобы успеть впитать производственные отходы, которые содержатся в почве и воздухе.
Они лучше переносят воздействие влаги и перепады температур. Кроме того, бамбуковый паркет считается самым экологичным отделочным материалом: стебли бамбука растут слишком быстро, чтобы успеть впитать производственные отходы, которые содержатся в почве и воздухе.
2. Определитесь с фактурой
Помимо древесины, стоимость паркета определяет его вид. Паркетная доска — самый бюджетный отделочный материал — продается полностью готовой к укладке, состоит из трех слоев, но производится из разных пород. Более дорогие материалы — массивная доска и штучный паркет — состоят из цельной древесины, но требуют специальных навыков при монтаже.
Специальный наборный паркет позволяет создавать на полу рисунки. Помимо классической «елочки», паркет можно выложить с окантовкой или поэкспериментировать с древесиной разных оттенков, чтобы получился узор «зебра». Кроме того, присутствие спилов и неидеальная структура верхнего слоя больше не считаются недостатками паркета: даже выложенные параллельно друг другу, такие доски будут выглядеть чувственно и колоритно.
3. Найдите свой цвет
Выбор оттенка паркета зависит от стиля помещения. Светлый сосновый или кленовый паркет хорошо впишется в скандинавский или минималистичный интерьер. Серая паркетная доска выразительно дополнит интерьер в желтых или бежевых тонах. Паркет желтого или коричневого оттенка легче всего вписать в интерьер: эти оттенки хорошо сочетаются с любыми другими цветами.
Не бойтесь экспериментировать с лакированным черным паркетом: глубокий темный цвет поможет создать графичный, элегантный интерьер. Только не забудьте дополнить его светлыми деталями — игра на контрасте сделает пространство более объемным. Еще один удачный прием — сочетать цвет паркета со столешницами или вертикальной поверхностью мебели: так интерьер будет выглядеть более целостным и гармоничным.
4. Нанесите покрытие
Чтобы паркет служил вам долгие годы, его придется покрыть маслом или лаком. При этом масло позволяет почувствовать структуру и тепло древесины под ногами, а лак закрывает древесные поры и ощущается как ровная глянцевая поверхность.
С первым материалом легче работать — справится даже человек без специальных знаний, но масляное покрытие придется обновлять в среднем раз в год. Лаковое покрытие более долговечно: о повторной шлифовке можно забыть на 6–7 лет. Если вы хотите постелить паркет в ванной комнате, покройте доски специальным водоотталкивающим раствором.
5. Учитывайте особенности помещения
Паркет может стать и инструментом моделирования проблемного пространства. Так, доски, положенные поперек комнаты, визуально расширят пространство, а широкий паркет будет выразительно смотреться в маленьком помещении. В остальных случаях паркет кладут вдоль от окна.
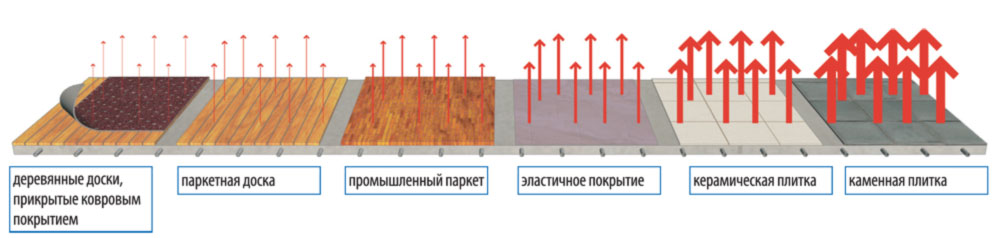
Широкий паркет неуместен в помещениях с резким перепадом температур и влажности: если зимой в квартире слишком сухо, доски вскоре покроются трещинами. Для таких квартир специалисты рекомендуют паркет до 110 миллиметров шириной.
Какая паркетная доска лучше, выбрать паркет для квартиры, выбор хорошего пола для дома
 org/BreadcrumbList»>
org/BreadcrumbList»>Паркет – один из самых дорогих и престижных видов напольных покрытий. Он привлекателен, практичен и долговечен. Материал с легкостью вписывается в разные по стилю интерьеры – от классики до авангарда. При должном уходе натуральный пол служит не менее 50 лет, поэтому в полной мере оправдывает свою стоимость. Однако к выбору паркетной доски следует подходить основательно. Чтобы правильно выбрать покрытие, следует учесть следующие факторы:
- внешний вид и фактуру планок;
- размер планок;
- характеристики.
Внешний вид
Чтобы паркет на протяжении многих лет не терял свою привлекательность и лоск, необходимо соответствующим образом подбирать цвет и декор материала. Самым непрактичным с точки зрения эксплуатации считается глянцевый однотонный паркет черного цвета. Да, он выглядит эффектно и дорого. Однако с течением времени все царапины на лаковой поверхности проявляются в виде белесых полос. Если вы хотите приобрести именно темную паркетную доску для своей квартиры, обратите внимание на варианты с матовым лаковым покрытием.
Самым непрактичным с точки зрения эксплуатации считается глянцевый однотонный паркет черного цвета. Да, он выглядит эффектно и дорого. Однако с течением времени все царапины на лаковой поверхности проявляются в виде белесых полос. Если вы хотите приобрести именно темную паркетную доску для своей квартиры, обратите внимание на варианты с матовым лаковым покрытием.
Если же в помещении уже установлены окна и двери из светлого массива, пол подбирается под их цвет и фактуру. Цвет пола также может сочетаться с мебелью и другими элементами интерьера. Визуально увеличить пространство комнат позволяют небольшие по размеру прямоугольные планки. Для просторных помещений правильнее будет выбрать доску средних и больших размеров.
Выбор паркета в магазине
Чтобы оценить конечный результат при выборе паркетной доски, лучше заранее ознакомиться с рекламными образцами непосредственно в магазине. Через монитор компьютера цвета передаются не точно, да и фактуру сложно будет оценить в полной мере.
Обязательно учитывайте, что большинство видов паркета со временем меняет свой цвет. Под воздействием света напольные покрытия способны темнеть, приобретать более насыщенные оттенки. К числу чувствительных пород относятся вишня, орех, береза и др.
Основные характеристики
Чтобы снизить к минимуму сезонные воздействия на паркет при изменении влажности и окружающей температуры, эксперты рекомендуют при покупке доски для дома изучить два основных параметра – твердость и стабильность. Первый показатель отвечает за практичность. Чем он выше, тем износоустойчивее пол. Измеряется твердость по Бринеллю по шкале от 1 до 5.
Второй показатель указывает на способность массива сохранять форму при изменении в квартире влажности и температуры. Данные измеряются по 5-бальной системе, где 1 – информирует о высокой чувствительности материала к влажной среде, а 5 – подтверждает стойкость материала к перепадам температур и атмосферным изменениям.
Показатель стабильности при выборе не менее важен, чем твердость. Например, бук по Бринеллю считается достаточно твердой породой (оценка 4), но при этом очень капризен к окружающим факторам – в зависимости от типа покрытия и обработки его стабильность составляет 1-2 единицы. Вышеперечисленные характеристики должны указываться в карточке товара в магазине.
Например, бук по Бринеллю считается достаточно твердой породой (оценка 4), но при этом очень капризен к окружающим факторам – в зависимости от типа покрытия и обработки его стабильность составляет 1-2 единицы. Вышеперечисленные характеристики должны указываться в карточке товара в магазине.
Для справки – в период отопления средний показатель влажности в квартирах нашего региона составляет порядка 25-30%, в теплые сезоны эта цифра превышает 65%-ый порог. Рекомендованная влажность для эксплуатации паркета составляет 45-60%.
Список статей
Что такое формат файла паркета? Варианты использования и преимущества
Содержание
Пытаетесь разобраться в концепциях озера данных? Мы написали практическое руководство, чтобы помочь вам в этом. В электронной книге рассматриваются руководящие принципы современной архитектуры озера данных, передовые методы хранения, конвейеры приема, обработки данных и многое другое. Получите это бесплатно здесь.
С момента своего первого появления в 2013 году Apache Parquet получил широкое распространение в качестве бесплатного формата хранения с открытым исходным кодом для быстрого выполнения аналитических запросов. Когда AWS объявила об экспорте озера данных, они охарактеризовали Parquet как 9.0011 «В 2 раза быстрее выгружается и занимает до 6 раз меньше места в Amazon S3 по сравнению с текстовыми форматами» . Преобразование данных в форматы столбцов, такие как Parquet или ORC, также рекомендуется как средство повышения производительности Amazon Athena.
Понятно, что Apache Parquet играет важную роль в производительности системы при работе с озерами данных.
Фактически, Parquet является одним из основных форматов файлов, поддерживаемых Upsolver SQLake, нашей платформой, полностью основанной на SQL, для преобразования данных в движении. Он может вводить и выводить файлы Parquet и использует Parquet в качестве формата хранения по умолчанию. Вы можете бесплатно выполнить образцы шаблонов пайплайна или начать создавать свои собственные в Upsolver SQLake.
Теперь давайте подробнее рассмотрим, что такое Parquet на самом деле и почему он важен для хранения и аналитики больших данных.
Основное определение: что такое паркет Apache?Apache Parquet — это формат файла, предназначенный для поддержки быстрой обработки сложных данных, с несколькими примечательными характеристиками:
1. Столбчатый: ориентированный — это означает, что значения каждого столбца таблицы хранятся рядом друг с другом, а не со значениями каждой записи:
2. Открытый исходный код: Parquet является бесплатным для использования и имеет открытый исходный код в соответствии с лицензией Apache Hadoop и совместим с большинством платформ обработки данных Hadoop. Цитируя веб-сайт проекта, «Apache Parquet… доступен для любого проекта… независимо от выбора платформы обработки данных, модели данных или языка программирования».
3. Самоописание : В дополнение к данным файл Parquet содержит метаданные, включая схему и структуру. В каждом файле хранятся как данные, так и стандарты, используемые для доступа к каждой записи, что упрощает разделение служб, которые записывают, хранят и читают файлы Parquet.
В каждом файле хранятся как данные, так и стандарты, используемые для доступа к каждой записи, что упрощает разделение служб, которые записывают, хранят и читают файлы Parquet.
Преимущества паркетного столбчатого хранения – зачем его использовать?
Приведенные выше характеристики формата файлов Apache Parquet создают несколько явных преимуществ, когда речь идет о хранении и анализе больших объемов данных. Рассмотрим некоторые из них более подробно.
Сжатие
Сжатие файла — это действие по уменьшению размера файла. В Parquet сжатие выполняется столбец за столбцом, и он создан для поддержки гибких параметров сжатия и расширяемых схем кодирования для каждого типа данных — например, для сжатия целочисленных и строковых данных может использоваться различное кодирование.
Данные паркета могут быть сжаты с использованием следующих методов кодирования:
- Кодирование по словарю: включается автоматически и динамически для данных с небольшим количеством уникальных значений.


- Упаковка битов: Хранение целых чисел обычно выполняется с выделенными 32 или 64 битами на целое число. Это позволяет более эффективно хранить небольшие целые числа.
- Кодирование длины цикла (RLE): , когда одно и то же значение встречается несколько раз, одно значение сохраняется один раз вместе с количеством вхождений. В Parquet реализована комбинированная версия упаковки битов и RLE, в которой переключение кодирования обеспечивает наилучшие результаты сжатия.
Производительность
В отличие от форматов файлов на основе строк, таких как CSV, Parquet оптимизирован для повышения производительности. При выполнении запросов в вашей файловой системе на основе Parquet вы можете очень быстро сосредоточиться только на соответствующих данных. Кроме того, объем сканируемых данных будет намного меньше, что приведет к меньшему использованию операций ввода-вывода. Чтобы понять это, давайте немного глубже рассмотрим структуру файлов Parquet.
Как мы упоминали выше, Parquet — это самоописываемый формат, поэтому каждый файл содержит как данные, так и метаданные. Файлы паркета состоят из групп строк, верхнего и нижнего колонтитула. Каждая группа строк содержит данные из одних и тех же столбцов. Одни и те же столбцы хранятся вместе в каждой группе строк:
Эта структура хорошо оптимизирована как для быстрой обработки запросов, так и для малого количества операций ввода-вывода (минимизация объема сканируемых данных). Например, если у вас есть таблица с 1000 столбцов, к которой вы обычно будете запрашивать только небольшое подмножество столбцов. Использование файлов Parquet позволит вам получить только необходимые столбцы и их значения, загрузить их в память и ответить на запрос. Если бы использовался формат файла на основе строк, такой как CSV, вся таблица должна была бы быть загружена в память, что привело бы к увеличению ввода-вывода и снижению производительности.
Эволюция схемы
При использовании форматов файлов со столбцами, таких как Parquet, пользователи могут начать с простой схемы и постепенно добавлять в схему дополнительные столбцы по мере необходимости.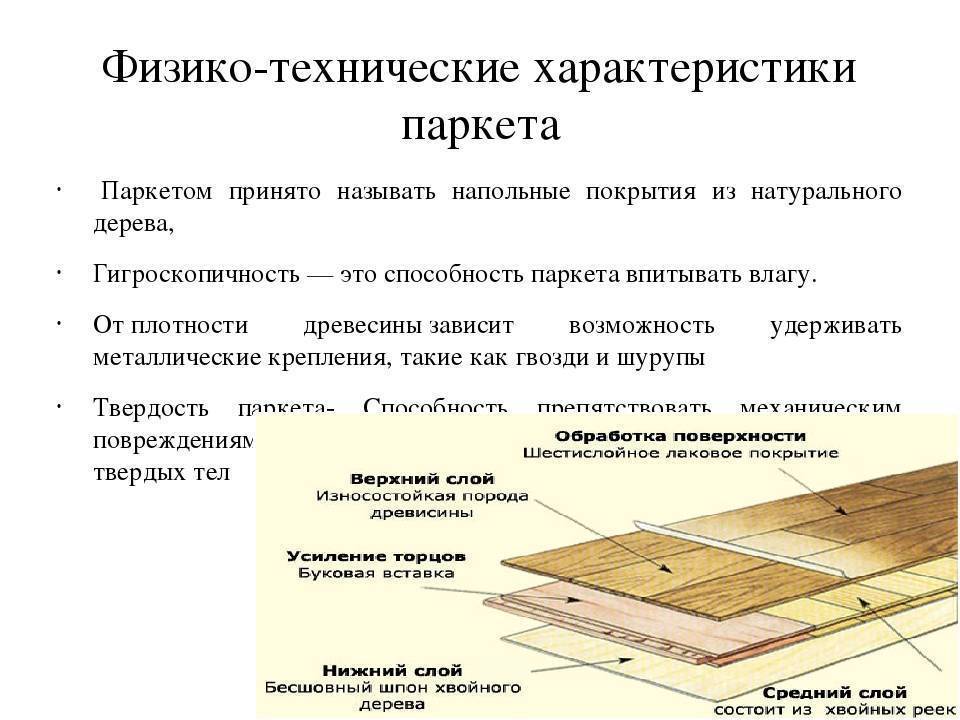 Таким образом, пользователи могут получить несколько файлов Parquet с разными, но взаимно совместимыми схемами. В этих случаях Parquet поддерживает автоматическое слияние схем между этими файлами.
Таким образом, пользователи могут получить несколько файлов Parquet с разными, но взаимно совместимыми схемами. В этих случаях Parquet поддерживает автоматическое слияние схем между этими файлами.
Apache Parquet является частью экосистемы Apache Hadoop с открытым исходным кодом. Усилия по разработке вокруг него активны, и он постоянно совершенствуется и поддерживается сильным сообществом пользователей и разработчиков.
Хранение данных в открытых форматах позволяет избежать привязки к поставщику и повысить гибкость по сравнению с проприетарными форматами файлов, используемыми во многих современных высокопроизводительных базах данных. Это означает, что вы можете использовать различные механизмы запросов, такие как Amazon Athena, Qubole и Amazon Redshift Spectrum, в рамках одной и той же архитектуры озера данных, а не привязываться к конкретному поставщику базы данных.
Хранилище, ориентированное на столбцы, и хранилище на основе строк для аналитических запросов Данные часто генерируются и легче концептуализируются в строках. Мы привыкли думать в терминах электронных таблиц Excel, где мы можем видеть все данные, относящиеся к конкретной записи, в одной аккуратной и упорядоченной строке. Однако для крупномасштабных аналитических запросов столбчатое хранилище имеет значительные преимущества в отношении стоимости и производительности.
Мы привыкли думать в терминах электронных таблиц Excel, где мы можем видеть все данные, относящиеся к конкретной записи, в одной аккуратной и упорядоченной строке. Однако для крупномасштабных аналитических запросов столбчатое хранилище имеет значительные преимущества в отношении стоимости и производительности.
Сложные данные, такие как журналы и потоки событий, должны быть представлены в виде таблицы с сотнями или тысячами столбцов и многими миллионами строк. Хранение этой таблицы в формате на основе строк, таком как CSV, будет означать:
- Запросы будут выполняться дольше, поскольку необходимо сканировать больше данных, а не только запрашивать подмножество столбцов, которые нам нужны для ответа на запрос (что обычно требует агрегирования). в зависимости от измерения или категории)
- Хранилище будет более дорогостоящим, поскольку файлы CSV не сжимаются так эффективно, как Parquet 9.0060
Столбцовые форматы обеспечивают лучшее сжатие и повышенную производительность, а также позволяют запрашивать данные по вертикали — столбец за столбцом.
Чтобы узнать, как Parquet сравнивается с другими форматами файлов, ознакомьтесь с нашим сравнением Parquet, Avro и ORC.
Хотя это неполный список, есть несколько явных признаков того, что вам следует хранить данные в Parquet:
- Когда вы работаете с очень большими объемами данных . Паркет создан для производительности и эффективного сжатия. Различные сравнительные тесты, в которых сравнивалось время обработки SQL-запросов в форматах Parquet и таких форматах, как Avro или CSV (включая один, описанный в этой статье, а также этот), обнаружили, что запросы Parquet приводят к значительно более быстрым запросам.
- Когда в вашем полном наборе данных много столбцов, но вам нужен доступ только к подмножеству . Из-за растущей сложности бизнес-данных, которые вы записываете, вы можете обнаружить, что вместо сбора 20 полей для каждого события данных вы теперь фиксируете более 100. Хотя эти данные легко хранить в озере данных, для их запроса потребуется сканирование значительного объема данных, если они хранятся в форматах на основе строк. Столбчатая и самоописывающая природа Parquet позволяет вам извлекать только те столбцы, которые необходимы для ответа на конкретный запрос, уменьшая объем обрабатываемых данных.
 Столбчатая и самоописывающая природа Parquet позволяет вам извлекать только те столбцы, которые необходимы для ответа на конкретный запрос, уменьшая объем обрабатываемых данных.
Столбчатая и самоописывающая природа Parquet позволяет вам извлекать только те столбцы, которые необходимы для ответа на конкретный запрос, уменьшая объем обрабатываемых данных.Если вы хотите, чтобы несколько служб использовали одни и те же данные из хранилища объектов . В то время как поставщики баз данных, такие как Oracle и Snowflake, предпочитают, чтобы вы хранили свои данные в проприетарном формате, который могут читать только их инструменты, современная архитектура данных смещена в сторону отделения хранилища от вычислений. Если вы хотите работать с несколькими аналитическими службами для решения различных задач, вам следует хранить данные в Parquet. (Подробнее об архитектуре конвейера данных)
Пример: Parquet, CSV и Amazon AthenaМы рассмотрели этот пример более подробно на нашем недавнем вебинаре с Looker. Смотреть запись здесь.
Чтобы продемонстрировать влияние столбцового хранилища Parquet по сравнению с альтернативами на основе строк, давайте посмотрим, что происходит, когда вы используете Amazon Athena для запроса данных, хранящихся в Amazon S3, в обоих случаях.
С помощью Upsolver мы передали набор данных журналов сервера в формате CSV на S3. В обычной архитектуре озера данных AWS Athena будет использоваться для запроса данных непосредственно из S3. Затем эти запросы можно визуализировать с помощью интерактивных инструментов визуализации данных, таких как Tableau или Looker.
Мы протестировали Athena на том же наборе данных, который хранится как сжатый CSV и как Apache Parquet .
Это запрос, который мы выполнили в Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage ОТ server_usage СГРУППИРОВАТЬ ПО tags_host ИМЕЕТ AVG (fields_usage_active)> 0 LIMIT 10
И результаты:
| CSV | Паркет | Столбцы | |
| Время запроса (секунды) | 735 | 211 | 18 |
| Отсканированные данные (ГБ) | 372,2 | 10,29 | 18 |
- Сжатые CSV: Сжатый CSV состоит из 18 столбцов и весит 27 ГБ на S3. Athena должна сканировать весь CSV-файл, чтобы ответить на запрос, поэтому мы будем платить за 27 ГБ отсканированных данных. При более высоких масштабах это также отрицательно скажется на производительности.
- Parquet: Преобразовывая наши сжатые файлы CSV в Apache Parquet, вы получаете аналогичный объем данных в S3. Однако, поскольку Parquet является столбцовым, Athena нужно считывать только те столбцы, которые имеют отношение к выполняемому запросу — небольшое подмножество данных. В этом случае Athena должна была просканировать 0,22 ГБ данных, поэтому вместо оплаты 27 ГБ отсканированных данных мы платим только за 0,22 ГБ.
 Athena должна сканировать весь CSV-файл, чтобы ответить на запрос, поэтому мы будем платить за 27 ГБ отсканированных данных. При более высоких масштабах это также отрицательно скажется на производительности.
Athena должна сканировать весь CSV-файл, чтобы ответить на запрос, поэтому мы будем платить за 27 ГБ отсканированных данных. При более высоких масштабах это также отрицательно скажется на производительности. Использование паркета — хорошее начало; однако на этом оптимизация запросов к озеру данных не заканчивается. Вам часто нужно очищать, обогащать и преобразовывать данные, выполнять соединения с высокой кардинальностью и внедрять множество передовых методов, чтобы обеспечить быстрые и экономичные ответы на запросы.
SQLake — новейшее предложение Upsolver. Он позволяет создавать и запускать надежные самоорганизующиеся конвейеры данных для потоковой передачи и пакетных данных с помощью интерфейса, полностью основанного на SQL. Вы можете использовать SQlake для упрощения конвейеров озера данных, автоматического приема данных в виде оптимизированного Parquet и преобразования потоковых данных с помощью функций, подобных SQL или Excel. Попробуйте бесплатно в течение 30 дней. Кредитная карта не требуется. Вы также можете запланировать демонстрацию, чтобы узнать больше.
Следующие шаги- Ознакомьтесь с некоторыми из этих передовых методов работы с озером данных.
- Прочтите о создании конвейеров приема больших данных
- Узнайте о преимуществах хранения вложенных данных в формате Parquet.
- Ознакомьтесь с нашим новым руководством по безопасным озерам данных, соответствующим требованиям.

Опубликовано в: Блог , Облачная архитектура
Parquet Передовой опыт: откройте для себя свои данные, не загружая их | Арли | Январь 2023 г.
Метаданные, статистика групп строк, обнаружение разделов и переразметка
Фото Jakarta Parquet на UnsplashЭта статья является следующей из серии статей о паркете. Вы должны проверить предыдущую статью
Apache Parquet — это столбчатый формат хранения для платформ больших данных, таких как Apache Hadoop и Apache Spark . Он предназначен для повышения производительности обработки больших данных за счет использования формата столбцового хранения , в котором данные хранятся в сжатом и эффективном виде.
Паркет Использование продолжает расти, поскольку все больше и больше организаций обращаются к технологиям больших данных для обработки и анализа больших наборов данных. В связи с этим непрерывным развитием важно, чтобы каждый изучил некоторые передовые методы и научился ориентироваться в Паркет файлов.
В этом руководстве мы покажем вам, как получить максимальное представление о ваших данных Parquet в качестве пользователя Parquet , не прибегая к обычной грубой силе загрузки их для понимания.
Для этого мы предоставим вам пример, в котором Data Engineer предоставил вам данные соискателей кредита, и вам необходимо создать прогнозные модели с этими данными. Но сначала нужно «технически» обнаружить данные. А это огромные данные.
Действительно, Data Engineer , подготовивший данные, говорит вам, что папка Parquet 1 ТБ большая (только для образовательных целей, в нашем примере это не так) , так что если вы попытаетесь загрузить все , вы столкнетесь с ошибкой памяти на своем компьютере.
Не волнуйтесь, мы предоставим вам самый эффективный способ понять большие данные Parquet , даже не загружая Паркет данных в памяти.
Это означает ответы на следующие вопросы:
- Как выглядят файлы Parquet в этой папке?
- Какие переменных находятся внутри? С чем набирает ? Какая-то статистика ?
- как разделены данные?
Мы также научим вас, как переформатировать разделы , если вы заметили, что что-то не так с разделением данных.
Импорт, который вам понадобится для этого урока:
import pyarrow as pa
import pyarrow.parquet as pq
import os
Прежде всего, мы хотим получить представление о том, что содержит папка ‘APPLICATIONS_PARTITIONED’ . , здесь хранятся данные.
Поскольку вы не знаете, как данные разбиты на разделы , вы не можете просто загрузить всю папку вслепую, потому что вы будете загружать все файлы Parquet , а это не то, что вы хотите делать (помните размер 1 ТБ), но вы хотите получить обзор ваших данных.
Здесь я даю вам функцию get_first_parquet_from_path() , которая вернет первый файл Parquet , находящийся в каталоге. Функция будет сканировать каждый каталог и подкаталог, пока не найдет файл Parquet , и вернет полный путь к этому единственному файлу.
def get_first_parquet_from_path(path):
для (dir_path, _, files) в os.walk(path):
для f в файлах:
if f.endswith(".parquet"):
first_pq_path = os.path. присоединиться (путь_каталога, f)
return first_pq_path
Похоже, классная функция, давайте применим ее на практике.
path = 'APPLICATIONS_PARTITIONED'
first_pq = get_first_parquet_from_path(path)
first_pq
#Output : APPLICATIONS_PARTITIONED/NAME_INCOME_TYPE=Commercial associate/CODE_GENDER=F/6183f182ab0b47c49cf56a3e09a3a7b1-0.parquet
We notice from the path that this is partitioned by NAME_INCOME_TYPE и CODE_GENDER , полезно знать.
Чтобы прочитать этот путь сейчас, чтобы получить количество строк и столбцов, а также драгоценные Схема вот что вы можете сделать:
first_ds = pq.
first_ds.num_rows, first_ds.num_columns, first_ds.schema
 read_table(first_pq)
read_table(first_pq) Запуск занял менее 1 секунды, причина в том, что read_table () читает файл Parquet и возвращает объект PyArrow Table , который представляет ваши данные в виде оптимизированной структуры данных, разработанной Apache Arrow .
Теперь мы знаем, что есть 637800 строк и 17 столбцов (+2 исходящих от пути), и у нас есть обзор переменных и их типов.
Подождите, я уже говорил вам, что нам не нужно ничего загружать в память, чтобы обнаружить данные. Итак, вот способ сделать это, не читая таблицы.
Я частично обманываю вас, потому что мы не будем загружать никаких данных, но мы будем загружать нечто, называемое метаданными .
В контексте формата файла Parquet метаданные относятся к данным, которые описывают структуру и характеристики данных, хранящихся в файле. Сюда входит такая информация, как типы данных каждого столбца, имена столбцов, количество строк в таблице и схема.
Сюда входит такая информация, как типы данных каждого столбца, имена столбцов, количество строк в таблице и схема.
Давайте использовать обе функции read_metadata() и read_schema() из pyarrow.parquet :
ts=pq.read_metadata(first_pq)
ts.num_rowsq, pnq.read_columnsЭто дает вам тот же результат, что и
read_table().Однако мы замечаем, что во времени выполнения есть большая разница, потому что здесь оно близко к мгновенному. И это неудивительно, ведь чтение метаданных похож на чтение очень небольшой части файла Parquet , который содержит все, что вам нужно для обзора данных.
Теперь предположим, что я хочу узнать немного больше о столбцах, что я могу сделать?
Вы можете прочитать статистику из первой группы строк файла.
Группа строк в формате файла Parquet представляет собой набор строк, которые хранятся вместе как единое целое и делятся на более мелкие фрагменты для эффективного запроса и обработки.
parquet_file = pq.ParquetFile(first_pq)
ts=parquet_file.metadata.row_group(0)
для nm в диапазоне (ts.num_columns):
print(ts.column(nm))Этот код выше даст вам уродливый вывод, вот некоторый код для форматирования его в красивый DataFrame:
beautiful_df = pd.DataFrame()
для nm в диапазоне (ts.num_columns):
path_in_schema = ts.column(nm).path_in_schema
сжатый_размер = ts.column(nm).total_compressed_size
статистика = ts.column(nm).statistics
минимальное_значение = статистика.мин
максимальное_значение = статистика.макс
физический_тип = статистика.физический_тип
красивая_df[путь_в_схеме] = pd.DataFrame([физический_тип, минимальное_значение, максимальное_значение, сжатый_размер])
df = красивая_df.T
df.columns = [ 'DTYPE', 'Min', 'Max', 'Compressed_Size_(KO)']В DataFrame у вас есть тип столбцов, минимальный, максимальный и сжатый размер. Несколько выводов из этого файла:

- Столбцы строк были преобразованы в BYTE_ARRAY .
- Минимум и максимум для строковых столбцов сортируются в алфавитном порядке.
- Размер сжатия Boolean не намного лучше, чем BYTE_ARRAY .
- Самому молодому заявителю 21 год, а самому старшему 68 лет.

Будьте осторожны, чтобы не обобщать статистику, это только из первого паркетного файла!
Отлично, теперь мы хорошо разбираемся в таких данных, как информация о столбцах, типах, схемах и даже статистиках, но ничего не упустили?
Да, мы не знаем разделов данных! Как было сказано ранее, мы могли бы угадать по крайней мере столбцы разделения по пути к файлу:
данные разделены на NAME_INCOME_TYPE и CODE_GENDER . Но мы не знаем других значений разделов. Предположим, что мы хотим посмотреть на другие NAME_INCOME_TYPE ?
Но я дам вам код, чтобы вы могли получить разделов более системным способом, а также все возможные значения для разделов :
def get_all_partitions(path):
partitions = {}
i = 0
for (_, partitions_layer, _) в os.
if len(partitions_layer)>0:
ключ = partitions_layer[0].split('=')[0]
partitions[key] = sorted([partitions_layer[i].split('=')[1] для i в диапазоне (len(partitions_layer))])
else:
break
return partitions
 walk(path):
walk(path): Давайте запустим эту функцию, которая возвращает словарь с ключами, соответствующими столбцам разделов, , а значения — это связанные значения разделов для каждого столбца раздела.
ps = get_all_partitions(path)
ps.keys(), ps.values()
Теперь мы знаем, что Data Engineer разделил данные сначала по Income_Type , а затем по Gender . И все значения для столбцов раздела перечислены ниже:
Теперь, когда у нас есть знания о столбцах раздела и значениях, мы можем прочитать другой интересующий нас раздел.
Предположим, что мы хотим прочитать все данные «Пенсионер» независимо от пола .
Из последнего урока мы знаем, что можем сделать это, прочитав папку Parquet 'APPLICATIONS_PARTITIONED/NAME_INCOME_TYPE=Pensioner'
df_pensioner = pd.Важно не разбивать данные на разделы, потому что, как правило, время выполнения увеличивается на количество разделов в папке. Таким образом, вы должны иметь в виду, что существует потенциальный недостаток разделов, даже если они делают данные более читаемыми с функциональной точки зрения. (Из официальной документации 512 МБ — 1 ГБ — оптимальный размер раздела).
Здесь, скажем, мы предполагаем, что вложенные папки полов достаточно малы после проверки данных, и мы обнаруживаем, что функциональное разделение полов бесполезно. Мы решили переформатировать набор данных, чтобы он был разделен только на name_income_type :
pq_table = pq.read_table ('applications_partitioned')
pq.write_to_dataset (PQ_TABL написал Паркет файл разбитый только на ИМЯ_ДОХОД_ТИП и не более на Пол .
 read_parquet('APPLICATIONS_PARTITIONED/NAME_INCOME_TYPE'=Pensioner не заинтересованы в разделении данных по полу, а размер данных позволяет нам считывать данные обоих полов без чрезмерного времени выполнения.
read_parquet('APPLICATIONS_PARTITIONED/NAME_INCOME_TYPE'=Pensioner не заинтересованы в разделении данных по полу, а размер данных позволяет нам считывать данные обоих полов без чрезмерного времени выполнения.